


最近看到一个视频,是关于王小波传奇的一生,正好很喜欢那首背景音乐,因此就放到这里了,后面复习的时候还可以听听,音乐特别能存载记忆,说不定多年以后看到这里还能感受到现在的心境。
注:这部分学习里面的一些配图是使用宫文学老师的,他的图片特别能精确的表达一些专业术语,
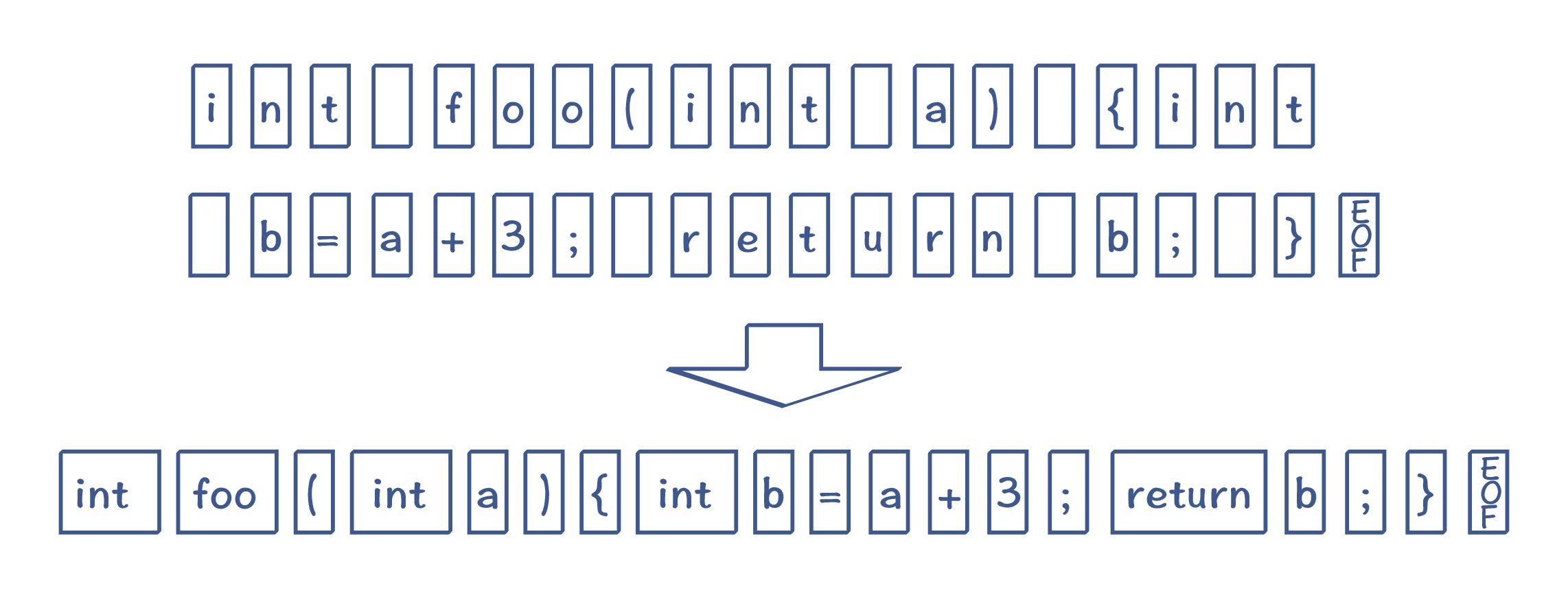
这是将一段程序转换为 Token 的过程,我们可以使用有限状态机来实现它。
有限状态机
有限自动机(Finite-state Automaton,FSA),或者叫做有限状态自动机(Finite-state Machine,FSM)。
是什么意思呢,其实就是一开始有一个初始状态,然后根据各自条件切换到各自状态的过程,比如,用户下单,产生一个订单,刚开始订单属于未支付的状态,它可能会迁移到已经支付的状态,也可能迁移到取消订单的过程。
去看看实际的例子吧,我们先来看看 GOLANG 的编译器怎么做词法分析的。
GOLANG 源代码词法分析主要有两个包,token 和 scanner 。token 包主要有 Token 的定义和 文件集的抽象 以及 位置相关的东西, scanner 扫描器,主要用于扫描源代码产生一个个 Token
type Token int
// The list of tokens.
const (
// Special tokens
ILLEGAL Token = iota
EOF
COMMENT
literal_beg
// Identifiers and basic type literals
// (these tokens stand for classes of literals)
IDENT // main true
INT // 12345
FLOAT // 123.45
IMAG // 123.45i
CHAR // 'a'
STRING // "abc"
literal_end
operator_beg
// Operators and delimiters
ADD // +
SUB // -
MUL // *
QUO // /
REM // %
AND // &
OR // |
XOR // ^
SHL // <<
SHR // >>
AND_NOT // &^
ADD_ASSIGN // +=
SUB_ASSIGN // -=
MUL_ASSIGN // *=
QUO_ASSIGN // /=
REM_ASSIGN // %=
AND_ASSIGN // &=
OR_ASSIGN // |=
XOR_ASSIGN // ^=
SHL_ASSIGN // <<=
SHR_ASSIGN // >>=
AND_NOT_ASSIGN // &^=
LAND // &&
LOR // ||
ARROW // <-
INC // ++
DEC // --
EQL // ==
LSS // <
GTR // >
ASSIGN // =
NOT // !
NEQ // !=
LEQ // <=
GEQ // >=
DEFINE // :=
ELLIPSIS // ...
LPAREN // (
LBRACK // [
LBRACE // {
COMMA // ,
PERIOD // .
RPAREN // )
RBRACK // ]
RBRACE // }
SEMICOLON // ;
COLON // :
operator_end
keyword_beg
// Keywords
BREAK
CASE
CHAN
CONST
CONTINUE
DEFAULT
DEFER
ELSE
FALLTHROUGH
FOR
FUNC
GO
GOTO
IF
IMPORT
INTERFACE
MAP
PACKAGE
RANGE
RETURN
SELECT
STRUCT
SWITCH
TYPE
VAR
keyword_end
)
Token 被分为4类, 特殊 token 、字面值 token、 操作符 token 和关键字 token 。这里只是把这些 token 作为 int 枚举常量,在后面会定义 token 数组,既:
var tokens = [...]string{
ILLEGAL: "ILLEGAL",
EOF: "EOF",
COMMENT: "COMMENT",
IDENT: "IDENT",
...
}
Go语言规范定义的基础面值主要有整数、浮点数和复数面值类型,此外还有字符和字符串面值类型。布尔类型的true和false并不在基础面值之类。但是为了方便词法解析,go/token包将true和false等对应的标识符也作为面值Token一类。
还有一些token 相关的函数,如
func (tok Token) String() string//Token 自带的String 方法,输出Token的具体值 12 => +func (op Token) Precedence()// 操作符的优先级- init 初始化关键字map
var keywords map[string]Token//示例 func => 71 func Lookup(ident string) Token检查一个 标识符。传入一个标识符,检查不是关键字 token就是 标识符 token.从这个函数的角度看,关键字和普通的标识符并无差别。但是25个关键字一般都是不同语法结构的开头Token,通过将这些特殊的Token定义为关键字可以简化语法解析的工作。func (tok Token) IsLiteral() boolfunc (tok Token) IsOperator() boolfunc (tok Token) IsKeyword() boolfunc IsExported(name string) bool是否是可以导出的字母,既是不是大写字母开头func IsKeyword(name string)判断是不是在初始化关键字的 keywords map里面func IsIdentifier(name string) bool是不是标识符字符串
func IsIdentifier(name string) bool {
for i, c := range name {
if !unicode.IsLetter(c) && c != '_' && (i == 0 || !unicode.IsDigit(c)) {
return false
}
}
return name != "" && !IsKeyword(name)
}
迭代这个字符串,如果是字母或者下划线”_”和数字组成的字符序列,并且不是字母开头,同时也不属于关键字,那么就是一个标识符,main, true , flase 这些都算。
接下来看看 token 报的文件、文件集、位置以及 pos
var src = []byte(`println("你好,世界")`)
var fset = token.NewFileSet()
var file = fset.AddFile("hello.go", fset.Base(), len(src))
首先我们需要知道的是 文件和文件集这些并不是真正的文件,他们不包含任何源代码,因为go包是多个文件组成的,多个包又组成程序,因此token 包的文件和文件集只是做了文件的抽象,为了方便定位 token 出现的 位置。
一个 File 结构体包含了一个文件集,每个文件集也反过来包含了 File 。文件集有多个文件,它把所有的文件看着是一个一维数组, 每个在这个一位数组里有自己的开始位置 base,名字和大小size。而其他的 Pos 可以看作是这个一维数组的下标,因此通过 Pos 下标可以找到是哪个文件和文件的偏移量 offset .反过来,知道 文件(base+offset)也可以算出 Pos。
因此,他们都没有任何源代码,只是帮助 定位 token 在哪个文件的那一行那一列。
比如扫描器返回一个 token 时会返回 tok 和 Pos 和字面值,我们可以调用 文件集 的 fset.Position 方法将 Pos 转换为具体位置
//接上面
var s scanner.Scanner
s.Init(file, src, nil, scanner.ScanComments)
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit)
}
扫描器结构体
type Scanner struct {
// immutable state
file *token.File // source file handle
dir string // directory portion of file.Name()
src []byte // source
err ErrorHandler // error reporting; or nil
mode Mode // scanning mode
// scanning state
ch rune // current character
offset int // character offset
rdOffset int // reading offset (position after current character)
lineOffset int // current line offset
insertSemi bool // insert a semicolon before next newline
// public state - ok to modify
ErrorCount int // number of errors encountered
}
将文件和代码初始化一个扫描器,不停的循环扫描,直到文件结束 EOF。接下来就是词法分析的关键,状态机了。
主体是一个switch case表示的状态机,
func (s *Scanner) Scan() (pos token.Pos, tok token.Token, lit string) {
scanAgain:
s.skipWhitespace() //跳过空格
// 当前 token 的 开始位置 ,offset 是每个文件的偏移,还记得上面说的base + size 就能得到 Pos吗?
pos = s.file.Pos(s.offset)
// determine token value
insertSemi := false //是否插入分号
switch ch := s.ch; {
case isLetter(ch): //如果当前字符串是字母
lit = s.scanIdentifier() //那就扫描标识符,如果后面连续是字母(下划线也包含)或者是数字就一直扫描,否则停止返回当前标识符(字母),注意这里扫描器offset和当前字符串会因为 next 函数一直往下一个字符
if len(lit) > 1 {
// keywords are longer than one letter - avoid lookup otherwise
tok = token.Lookup(lit) //检查这个标识符,如果是关键字就返回关键字的token,否则就是标识符token
switch tok {
case token.IDENT, token.BREAK, token.CONTINUE, token.FALLTHROUGH, token.RETURN:
insertSemi = true
}
} else {
insertSemi = true
tok = token.IDENT
}
case isDecimal(ch) || ch == '.' && isDecimal(rune(s.peek())): //如果是数字,或者是 . 并且下一位是数字
insertSemi = true
tok, lit = s.scanNumber()//扫描数字,然后向后看一次小数字再扫描数字,直到没有数字为止.
default:
s.next() // always make progress
switch ch {
case -1: //如果文件结束了 Eof
if s.insertSemi {
s.insertSemi = false // EOF consumed
return pos, token.SEMICOLON, "\n"
}
tok = token.EOF
case '\n':
// we only reach here if s.insertSemi was
// set in the first place and exited early
// from s.skipWhitespace()
s.insertSemi = false // newline consumed
return pos, token.SEMICOLON, "\n"
case '"': //如果是 引号开始就扫描字符串直到 引号结束
insertSemi = true
tok = token.STRING
lit = s.scanString()
case '\'':
insertSemi = true
tok = token.CHAR
lit = s.scanRune()
case '`':
insertSemi = true
tok = token.STRING
lit = s.scanRawString()
case ':':
tok = s.switch2(token.COLON, token.DEFINE)
case '.':
// fractions starting with a '.' are handled by outer switch
tok = token.PERIOD
if s.ch == '.' && s.peek() == '.' {
s.next()
s.next() // consume last '.'
tok = token.ELLIPSIS
}
case ',':
tok = token.COMMA
case ';':
tok = token.SEMICOLON
lit = ";"
case '(':
tok = token.LPAREN
case ')':
insertSemi = true
tok = token.RPAREN
case '[':
tok = token.LBRACK
case ']':
insertSemi = true
tok = token.RBRACK
case '{':
tok = token.LBRACE
case '}':
insertSemi = true
tok = token.RBRACE
case '+':
tok = s.switch3(token.ADD, token.ADD_ASSIGN, '+', token.INC)
if tok == token.INC {
insertSemi = true
}
case '-':
tok = s.switch3(token.SUB, token.SUB_ASSIGN, '-', token.DEC)
if tok == token.DEC {
insertSemi = true
}
case '*':
tok = s.switch2(token.MUL, token.MUL_ASSIGN)
case '/':
if s.ch == '/' || s.ch == '*' {
// comment
if s.insertSemi && s.findLineEnd() {
// reset position to the beginning of the comment
s.ch = '/'
s.offset = s.file.Offset(pos)
s.rdOffset = s.offset + 1
s.insertSemi = false // newline consumed
return pos, token.SEMICOLON, "\n"
}
comment := s.scanComment()
if s.mode&ScanComments == 0 {
// skip comment
s.insertSemi = false // newline consumed
goto scanAgain
}
tok = token.COMMENT
lit = comment
} else {
tok = s.switch2(token.QUO, token.QUO_ASSIGN)
}
case '%':
tok = s.switch2(token.REM, token.REM_ASSIGN)
case '^':
tok = s.switch2(token.XOR, token.XOR_ASSIGN)
case '<':
if s.ch == '-' {
s.next()
tok = token.ARROW
} else {
tok = s.switch4(token.LSS, token.LEQ, '<', token.SHL, token.SHL_ASSIGN)
}
case '>':
tok = s.switch4(token.GTR, token.GEQ, '>', token.SHR, token.SHR_ASSIGN)
case '=':
tok = s.switch2(token.ASSIGN, token.EQL)
case '!':
tok = s.switch2(token.NOT, token.NEQ)
case '&':
if s.ch == '^' {
s.next()
tok = s.switch2(token.AND_NOT, token.AND_NOT_ASSIGN)
} else {
tok = s.switch3(token.AND, token.AND_ASSIGN, '&', token.LAND)
}
case '|':
tok = s.switch3(token.OR, token.OR_ASSIGN, '|', token.LOR)
default:
// next reports unexpected BOMs - don't repeat
if ch != bom {
s.errorf(s.file.Offset(pos), "illegal character %#U", ch)
}
insertSemi = s.insertSemi // preserve insertSemi info
tok = token.ILLEGAL
lit = string(ch)
}
}
if s.mode&dontInsertSemis == 0 {
s.insertSemi = insertSemi
}
return
}
这个函数就是扫描一个个 token 出来。其中包含了 token pos 和字面值,这样把源文件通过扫描产生一个个 token 的过程就是tokenize或者lexical analysis的过程。词法分析中用到状态机是为了解决“当前 token 识别后下一步怎么处理”的问题。
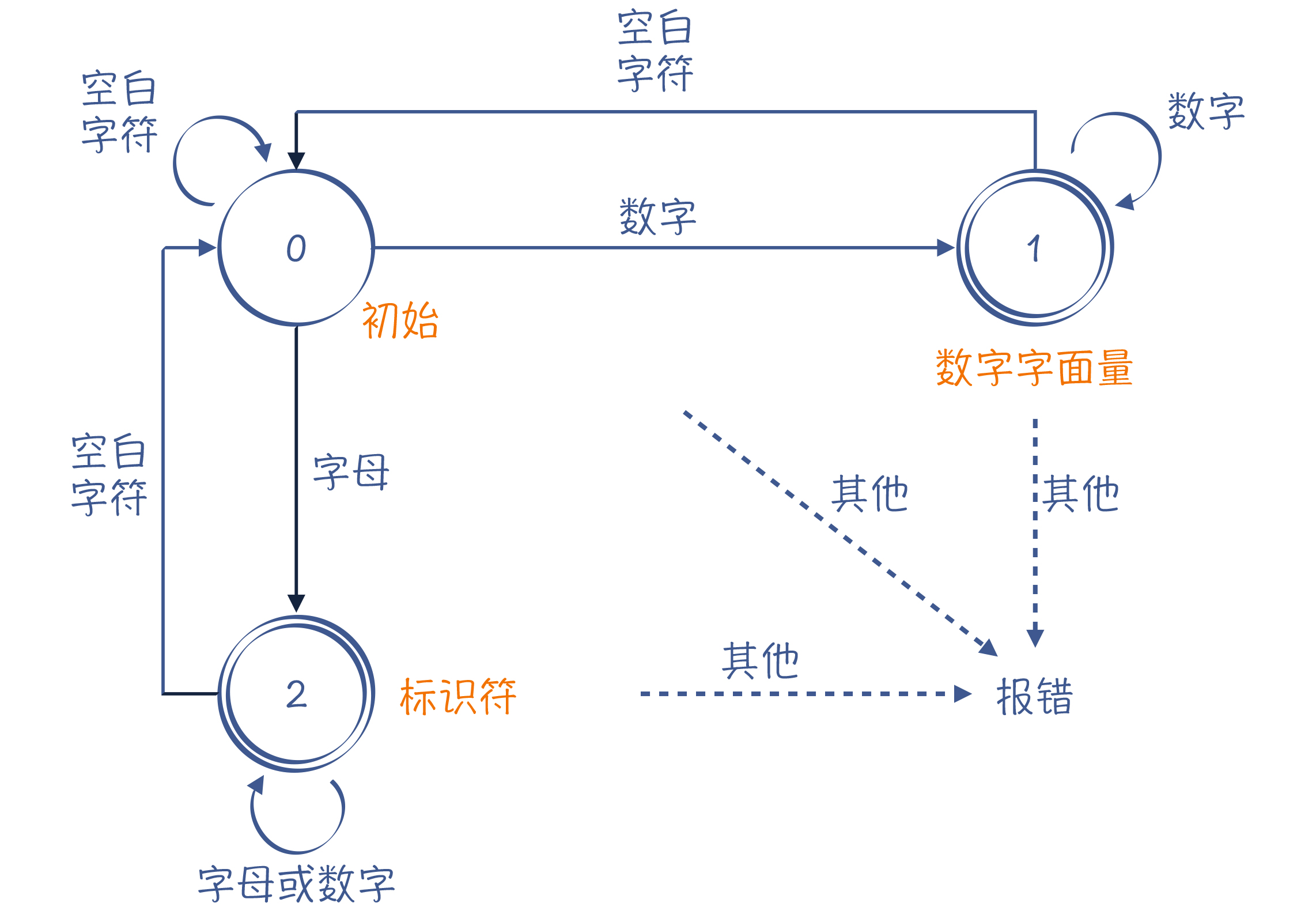
比如这个状态机就是表示开始跳过空白字符,如果是数字就接着扫描,直到空白字符跳转到状态1并记下这个数字,并返回状态0,如果遇见字母就接着扫描,直到空白字符跳转到状态2并记下这个字母开头有数字的标识,并返回状态0。
这种计算模型叫做有限自动机(Finite-state Automaton,FSA),或者叫做有限状态自动机(Finite-state Machine,FSM)。
词法分析的过程,其实就是对一个字符串进行模式匹配的过程,正则表达式也可以用来描述词法规则,这种描述方法,我们叫做正则文法(Regular Grammar)
Regular Grammar:
Int : int; //int关键字
For : for; //for关键字
IntLiteral : [0-9]+; //至少有一个数字
Id : [A-Za-z][A-Za-z0-9]*; //以字母开头,后面可以是字符或数字
Token 类型: 正则表达式” 这种格式,用于匹配一种 Token。仔细观察会发现Id的正则文法是可以匹配Int的正则文法的,即int关键字也有可能被识别为Id的Token,所以我们得要约定优先级,比如在前面的优先级更高等。
上面的词法分析都是手写词法分析器,词法分析器生成工具 lex(及 GNU 版本的 flex)可以根据正则文法自动生成词法分析器。lex 可以把正则表达式翻译成 NFA,然后把 NFA 转换成 DFA。
- NFA => “Nondeterministic Finite Automaton”的缩写,即不确定的有限自动机,该状态机中存在某些状态,针对某些输入,不能做一个确定的转换。
- DFA => “Deterministic Finite Automaton”的缩写,即确定的有限自动机,该状态机在任何一个状态,基于输入的字符,都能做一个确定的状态转换。前面例子中的有限自动机,都属于 DFA。
关于更多的NFA和DFA的知识我们先抛开,不管怎么说,到这里我们已经得到了Token 串,后面我将继续学习怎么将 Token 串转化成 AST, 即语法分析阶段。