


前言
因为人工智能的火热,组了一台13700K+4070的主机,想着要拿来跑图和跑模型学习,结果打开了steam下载了只狼嘎嘎炫,还好玩了几天就对游戏失去兴趣了,后面跑图就不说了(各种模型和LORA让人眼花缭乱,狗头.jpg),然后给别人开发了一个对接chatgpt的系统后,觉得要找一个开源本地能跑的LLM玩一玩,然后就发现了清华大学的ChatGLM2-6b,跑起来发现效果还行,这样的话不就可以用最少的代价建立起本地知识库问答机器人了?so 今天我们就研究一下基于AGI的向量实现语义搜索,并给聊天机器人提供更多的上下文从而建立自己的知识库问答机器人。关键词:ChatGLM2-6b、embedding、llama_index、cuda、pytorch
环境
- python 3.10
- CUDA V11.6。 在 NVIDIA 的 GeForce Experience 是没有这个的,CUDA工具包需要到 NVIDIA 官网下载的。地址
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local,安装后通过命令nvcc --version查看是否安装成功和安装的版本号。 - pytorch Stable (2.0.1)。pytorch的安装会有兼容性问题,需要到pytorch官网正确选择安装命令
https://pytorch.org/get-started/locally/。我的安装命令是pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu116 - llama_index V0.7.3
- 梯子 。终端也要走,要不然寸步难行。
原理
现在像 openai 和 ChatGLM2-6B 等大模型语言的对话上下文是有 token 限制的,即使是 gpt 4 目前最好的模型好像也是 32k,对于我们的本地资料库,肯定是需要通过语义搜索出相关的段落,将相关段落和用户的提问一起给到语言模型去回答。例如:
`
${content}。
根据以上信息,请回答下面的问题:Q: ${question}
`
那么怎么才能利用模型来做语义搜索呢?
首先获得所有资料库句子的语义向量(Embedding),将用户的提问也转换为语义向量,通过计算问题的向量和资料库所有向量的余弦相似度,从而找到语义相似的多条资料,在利用语言大模型的上下文推理逻辑来精准回答用户问题。
这里的搜索并不是像以前一样简简单单的分词匹配,他也是利用sentence-similarity(句子相似度)相关的预训练模型来完成的。
#SentenceSimilarity Models & Embedding
openai 提供了一个接口可以直接生成Embedding,它使用的是 openai-ada-002 模型。我将当前这个博客所有的md文档试了一下,慢不说,还消耗了我的0.2美元。所以我们肯定要使用开源的,下面是部分模型对比。
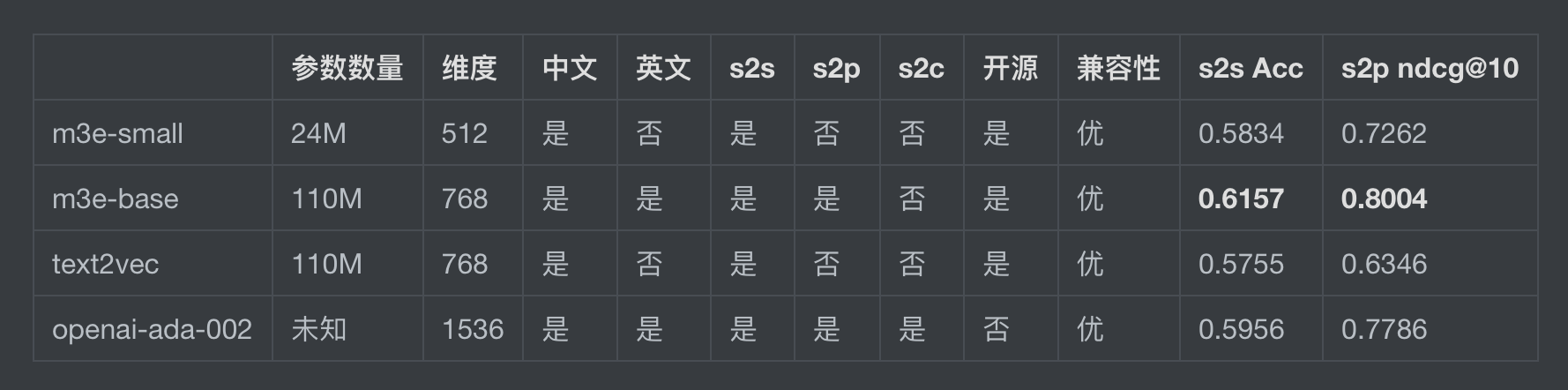
现在在huggingface排第一的是GanymedeNil/text2vec-large-chinese,但是我更建议使用m3e-base,text2vec 还不支持英文,注意:m3e-base还不支持代码检索。
要使用这些模型库,我们需要安装sentence-transformers,它是一个用于生成句子嵌入(sentence embeddings)的Python库,它基于预训练模型,并提供了简单易用的接口来计算句子之间的语义相似度和进行句子级别的语义搜索。
sentence-transformers使用了两个主要的技术来计算句子嵌入:
- 序列编码器(Sequence Encoder):使用预训练的模型来将句子编码成固定长度的向量表示。这些模型可以通过逐层预训练和微调学习到句子的上下文和语义信息。
- 相似性度量:使用余弦相似度或欧几里得距离等度量方法来计算两个句子之间的相似度。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
sentences = ['我有一只哈基米','The quick brown fox jumps over the lazy dog.']
sentence_embeddings = model.encode(sentences)
for sentence, embedding in zip(sentences, sentence_embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
输出:
Sentence: 我有一只哈基米
Embedding: [ 1.14187300e+00 9.20354187e-01 9.80630457e-01 -5.97655118e-01
3.48968148e-01 -1.51562333e+00 4.05094117e-01 8.58210683e-01
-3.41794074e-01 -8.43169689e-02 1.09149730e+00 2.21264869e-01
3.20232630e-01 -1.35299790e+00 -1.51560438e+00 -1.13328314e+00 ...]
...
这个库还提供了搜索和计算余弦距离等工具函数,甚至是图片和文本都可以一起嵌入计算,当然得模型支持。
https://huggingface.co/moka-ai/m3e-base
https://github.com/UKPLab/sentence-transformers
名词解释
来自chatgpt:
Embedding(嵌入)是将文本或单词映射到连续向量空间的过程。在自然语言处理中,我们可以使用预训练的词嵌入模型(如Word2Vec、GloVe或BERT)将单词、短语或句子嵌入到低维向量表示中。这种连续向量表示可以捕捉到词语之间的语义和上下文关系。
Sentence Similarity(句子相似度)是衡量两个句子之间语义上的相似性或相关性的度量。在自然语言处理任务中,如问答系统、信息检索和文本摘要等应用中,需要判断两个句子之间的相似度。通过将句子嵌入到连续向量空间中,我们可以使用向量之间的相似度度量(如余弦相似度或欧氏距离)来衡量句子的相似性。
具体而言,通过将句子转换为嵌入向量,我们可以使用向量之间的距离或相似度来度量两个句子之间的相关性。如果两个句子在嵌入空间中的向量表示相似,那么它们很可能具有相似的含义或语义。因此,通过比较句子的嵌入向量,我们可以计算句子之间的相似度分数,从而评估它们的相关性。
Llama Index
如果我们手动将各种文档(text、pdf、word、sql)分好句子段落,然后都生成Embedding,在保存起来是一件很繁琐的事情,所以可以使用Llama Index快速帮我们完成这些工作。
https://github.com/jerryjliu/llama_index
建立知识库向量
默认使用openai 接口,需要设置OPENAI_API_KEY。
import os
os.environ["OPENAI_API_KEY"] = 'OPENAI_API_KEY'
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('blog_docs/content').load_data()
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist()
如果不使用openai自定义Embedding
from llama_index import VectorStoreIndex, SimpleDirectoryReader,LangchainEmbedding,ServiceContext
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embed_model = LangchainEmbedding(HuggingFaceEmbeddings( model_name="moka-ai/m3e-base"))
service_context = ServiceContext.from_defaults(embed_model=embed_model)
documents = SimpleDirectoryReader('blog_docs/content').load_data()
index = VectorStoreIndex.from_documents(documents,service_context=service_context,)
index.storage_context.persist()
这样可以在本地简单的建立一个 Embedding storage,如果想要更快的检索可以配合使用FAISS。推荐使用 Facebook 开源的 Faiss 这个 Python 包,它的全称就是 Facebook AI Similarity Search,也就是快速进行高维向量的相似性搜索。
llama_index 自定义 Embedding 文档地址 https://github.com/jerryjliu/llama_index/blob/main/docs/how_to/customization/embeddings.md
查询
from llama_index import LangchainEmbedding,ServiceContext
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name="moka-ai/m3e-base"))
service_context = ServiceContext.from_defaults(embed_model = embed_model)
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir='./storage')
index = load_index_from_storage(storage_context,service_context=service_context)
query_engine = index.as_query_engine(response_mode="no_text")
resp = query_engine.query("ForestBlog 是什么?")
for node in resp.source_nodes:
print(node.node.text)
这样就能检索出相似度的句子了。查询的时候如果不设置 response_mode="no_text" 的话就会自动添加上下文然后去 openai 哪里查询(需要key)。
下一步我们不使用openai,试试ChatGLM2-6b的上下文推理效果。
ChatGLM2-6b
安装
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
然后使用 pip 安装依赖:
pip install -r requirements.txt
其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
在使用ChatGLM2-6b时,开源代码提供了 cli_demo.py 可以简单的在终端使用对话,但是如果你是win用户的话,需要安装pyreadline来代替readline包,修改导入为 import pyreadline as readline
20231010补充
对于使用 golang,有一个使用 rust 并开源的向量数据库 qdrant ,它提供了 Golang Sdk
https://github.com/qdrant/qdrant
https://github.com/qdrant/go-client
当然也有其他客户端SDK ,比如 typescript,python等。
使用 docker 安装下
docker run -p 6333:6333 qdrant/qdrant
保存向量数据的时候,除了 Vector Data 之外我们还要保存其他一些额外信息(问答、数据ID、引用地址等),这样后续通过向量搜索出来的内容可以快速定位相关内容。