


今天来梳理一下计算机中的鬼画符😂正则表达式 , 在平时的工作中,我们很多地方都会使用到正则,但是实际使用频率并没有那么高,因此很多时候都是去网上查一下修改修改就用了,但是过一段时间就会忘记,每次使用都得回忆理解一些元字符,其实还是比较浪费时间的,正则作为一种生命周期很长的技术,我觉得可以花一些时间去梳理一下,方便必要时候查询。目前正则有两大流派(Flavor):POSIX 流派与 PCRE 流派,不过在大体上都差不多,我们不在区别具体的细节。
正则可视化工具
- https://regex101.com/ 支持各种语言的在线正则
- http://wangwl.net/ 在线验证工具
- https://regexr.com/ 在线验证工具
- https://regexper.com/ 正则铁路图
元字符
元字符就是指那些在正则表达式中具有特殊意义的专用字符,比如\d。而普通字符表示的还是原来的意思,比如d匹配的就是文本里面的字符d。元字符是正则里面非常重要同时又是难以记忆的东西,我们对他分类理解。
辅助记忆
d 是 digit 数字
w 是 word 单词
s 是 space 空白
- 特殊字符(基础元字符)
.任意字符,除换行符外\d任意数字,\D任意非数字\w任意字母数字下划线,\W任意非字母数字下划线\s任意空白符,\S任意非空白符。
- 空白符
\r回车符\n换行符\f换页符\t制表符\v垂直制表符\s任意空白符
- 量词 (基础元字符匹配的是单个字符,如\d匹配出现过一次的数字,能匹配到多个)
*0到多次+1到多次?0到1次{m}出现m次{m,}出现至少m次{m,n}出现m到n次
- 范围
|或,a|b 匹配a或者b ,(多分支选择都是左边的优先)[abcdefg]多选一,括号中任意一个元素[a-z]匹配a到z之间的任意一个元素[^abcdefg]取反,不能是括号中的任意一个元素 ,如[^a-z|A-Z]不能是大小写字母
- 断言 (Assertions) 边界限定 (其他的正则只是匹配文本内容本身,而断言不仅要求文本内容本身的匹配还要求它出现的位置)
- 单词边界 使用
\b来限定单词边界,例如word\b只能匹配单词word,words就不行 - 行的开始/结束 ,在一行文本开头或结尾,就可以使用 ^ 和 $ 来进行位置界定。
- 环视,即瞻前顾后,找准定位。
(?<=Y)左边是Y,(?<!Y)左边不是Y,(?=Y)右边是Y,(?!Y)右边不是Y。需要注意的是向左看的时候需要放在表达式左边,向右看的时候需要放在表达式右边。
- 单词边界 使用
提示:
- 不同的系统在每行文本结束位置默认的“换行”会有区别,在 Windows 里是 \r\n,在 Linux 和 MacOS 中是 \n。
- 中括号[]代表多选一,可以表示里面的任意单个字符,所有不需要管道符号“|”。另外,中括号中,我们还可以用中划线表示范围
- 字符组和多选结构,[]是字符组,本身带有多选一属性,而多选结构可以用
(ab|cd)表示
示例:
(https?|ftp):\/\/ http://或者https://或者ftp://,问号代表s有或者无
1[3-9]\d{9} 匹配11位手机号,1开头紧接着3到9中的一个数,然后接着9个数字
量词的贪婪、非贪婪、独占模式
有如下字符串aaabb在正则全局(global)匹配模式下我们可以看到正则a+出现一次匹配,匹配上了字符串aaabb其中的aaa, +这个正则量词元字符表示的是1到多次,也可以用{1,}代替,但是我们仔细理解的话,我们会发现如果单独匹配每一个a也满足+这个描述,如果那样的话就应该是匹配是三次,每次分别是a啊,为什么只匹配一次??为什么要按最长的三个a来匹配???注意了,这里的最长其实就是所谓的贪婪模式,在正则中,所有的量词默认都是贪婪模式,而非贪婪模式会尽可能短地去匹配。
- 贪婪:尽可能多地去匹配。
- 非贪婪:尽可能短地去匹配。
再来看一个例子,加深理解。还是字符串aaabb,有正则a*,默认贪婪模式会匹配5次,这5次分别如下:
- 0-3 aaa
- 3-3 //这里匹配到了空的字符串
- 4-4 //这里匹配到了空的字符串
- 5-5 //这里匹配到了空的字符串
- 6-6 //这里匹配到了空的字符串
量词* 相当于{0,},可匹配零次。其实如果是非贪婪模式的话,那是不是都会匹配0次了呢?
在量词后面加上英文的问号 ? 就会开启非贪婪匹配(Lazy)模式。
正则a*?匹配如下:
- 0-0
- 1-1
- 2-2
- 3-3
- 4-4
- 5-5
- 6-6
全部匹配到了空的字符串,总共匹配7次。正则a{1,3}默认匹配一次,a{1,3}?会匹配三次。
又例如:
有html <div></div>,正则</?.*>匹配一次,正则</?.*?>(非贪婪)匹配两次。
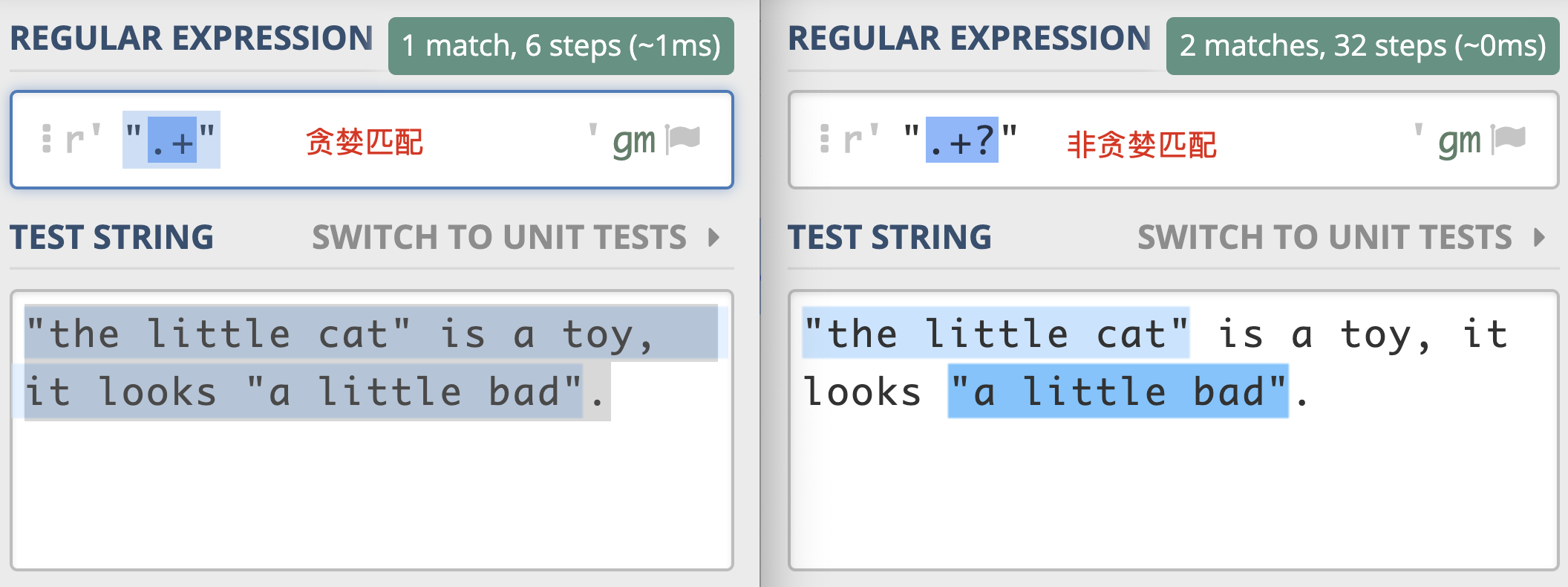
涂伟忠老师的图,贪婪和非贪婪模式的区别。
独占模式
这个模式很少用,像GOLANG就不支持,独占模式是用来避免向前回溯的,一般是在量词前面添加一个 +号,如a{1,3}+ab,
在正常的贪婪模式下,如果用 xy{1,3}z 去匹配 xyyz 字符串,y{1,3} 会尽量匹配字符串y,因此会向前匹配到位置3,接着字符串中后面是个 z 就会导致匹配不上,这时候正则就会向前回溯。
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯。
如果用 a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 使用贪婪模式会把前面三个 a 都用掉,并且不会回溯,这样字符串中内容只剩下 b 了,导致正则中加号后面的 a 匹配不到符合要求的内容,匹配失败。
如果要深刻理解独占模式的话可能需要对正则的状态机有所了解。
小括号(Capture捕获)和分组引用
即添加小括号(),在正则中如果添加小括号有两个意义,分别是:
- 当我们需要把一部分元字符看作一个整体的时候
- 当我们需要保存一个子组(子表达式)用来引用时
- 先来看当我们需要把一部分元字符看作一个整体的时候,需要添加
(?:),例如
\d{15}(?:\d{3})? 表示匹配15个数字后面的3个数字可有可无,如果我们不用小括号来包含\d{3}的话,正则就是\d{15}\d{3}? 表达的意思就变成了`匹配15个数字紧跟着使用非贪婪模式匹配3个数字,这里不加?:也是可以的,\d{15}(\d{3})? 也有相同的意义,只不过不加?:的小括号括起来的部分“子表达式”会被保存成一个子组,所以我们这里只是把一部分元字符看作一个整体,不需要子组功能的时候可以添加?:可以提高正则的性能。
在小括号里面添加?:表示不保存子组,括号只用于归组,把某个部分当成“单个元素”,不分配编号,后面不会再进行这部分的引用。注意,在断言环视的小括号却没有这个规则。
- 小括号的第二个功能,保存子组(子表达式)并可以引用和替换,并且每个子组都有自己的编号,它们分别从左到右编号依次递增。
例如正则表达式(ab)(c)\1有两个子组,它们分别是编号为1的子组ab,和编号为2的子组c。然后后面的\1表示引用子组编号为1的表达式,那么这个正则展开就是abcab,或者理解成(ab)(c)(ab)也可以,不过在这里括号可以去掉。
通过上面的例子,我们知道使用小括号保存子组可以在利用,使用小括号加?:不保存子组,不能再次利用,仅仅只是把部分表达式看着一个整体。
注意,golang 官方的正则库是不支持子组引用的。并且在实际替换的时候每种语言还有一些细微的差别,比如js在查找匹配的时候引用使用\1,但是替换时用$1来指定要替换的子组。
name = "abcabdefg";
console.log(/(ab)(c)\1/.test(name))
name.replace(/(ab)(c)\1/,"$2$1");
//输出:
//true
//"cabdefg" $2$1将查找过程中的子组互换位置替换
name = "abcabdefg";
name.replace(/(ab)(c)\1/,"$2-$1");
//输出 "c-abdefg"
再来看看括号嵌套的情况下编号是怎样的。

可以看到,简单场景下我们直接使用这种默认的子组编号没啥问题,但是复杂的情况下是不方便使用的,并且修改了括号位置得重新梳理子组编号,既然是默认的方式,那说明还有其他方式,是的,我们不仅可以使用默认的编号也可以给子组命名。命名分组的格式为(?P<分组名>正则),但是好像子组命名和引用每种语言都是不一样的,平时候不太建议使用。
例如js的子组命名和引用是 (?<myname>ab)(c)\k<myname>,php的则是 (?P<myname>ab)(c)(?P=myname)。
JS例子:
name = "abcabdefg";
console.log(/(?<myname>ab)(?<myname2>c)\k<myname>/.test(name))
name.replace(/(?<myname>ab)(?<myname2>c)\k<myname>/,"$<myname2>$<myname>");
//输出
//true
//"cabdefg"
//没错,js是使用(?<分组名>正则) 来命名子组的
//再来看看使用场景
const re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
const {groups: {day,month, year}} = re.exec('1999-12-31');
对此,go官方正则库也是不支持的,舍去一些不常用的正则以提高性能???
在来一个例子加深理解
let s = "the little cat cat is in the hat hat hat, we like it."
//需要将上面重复的单词替换为一个
s.replace( =/(\w+)(\s\1)+/g,"$1")
// 更严谨一点添加断言单词边界 => (\b\w+)(\s+\1\b)+
常用匹配模式
- 不区分大小写模式(Case-Insensitive)
- 单行匹配模式(Single Line)== 点号通配模式(Dot All)
- 多行匹配模式(Multiline)
- 注释模式(Comment)
开启模式的方法可以在正则后面添加关键字,也可以通过在正则前面使用(? 模式标识) 的方式来表示
- 之前我们经常在正则最后添加一个小写字母i来表示不区分大小写,例如
/cat/i,这样就能表示整个正则不不区分大小写,他们能匹配cat、Cat、CAt、CAT,除了这种方式我们也可以使用(?i)cat,就是在这正则前面添加(?i),还有一种情况,那就是我只希望匹配cat或者Cat,即只有第一个C才忽略大小写,通过前面的学习我们知道可以使用c|Cat,那么如何改变其中一个子表达式的模式呢?我们可以通过((?i)c)at,为了提高性能,我们不需要子组则可以使用(?:(?i)c)at。 - 单行匹配模式我们记为点号通配模式,可以使用
/.*/s或者(?s).*来开启此模式,此模式表示的是我们的元字符.开启 任意字符包括除换行符,即让.真正意义上的匹配"任意"。 - 多行匹配模式是针对
^和$符号的,我们知道^匹配整个文本的开头,$匹配整个文本的结尾。如果开启此模式的话就不是整个文本了,而是每一行。例如(?m)^cat|sf$匹配每一行文本的cat和sf,但是必须要求他们是cat开头或者是sf结尾。 - 注释模式(Comment)即在正则当中添加注释。例如
(\w+)(?#word) \1(?#word repeat again),貌似go官方库也不支持。😂
注意,js 是后面才支持使用(? 模式标识) 来开启模式,因此某些在线工具可能无法使用。
常用的正则基本就是这些内容了,最后需要留意下一些细节和各种小括号表示的意义。
- 量词后面添加?号使用懒惰匹配,添加+号是使用独占匹配。
- 表达式前面添加小括号加问号再加匹配模式符号表示启用某个匹配模式,如(?i)、(?s)、(?m)、(?#注释)
- 小括号还可以把部分表达式看作一个整体如:(?:表达式),也可以启用子组(捕获)如:(表达式)。
- 小括号还可以用作断言,如:
(?<=Y)左边是Y,(?<!Y)左边不是Y,(?=Y)右边是Y,(?!Y)右边不是Y。
理解案列
/^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{6,18}$/大小写+数字组成,字数6-18位/^(\d|[1-9]\d|100)(\.\d{1,2})?$/0-100数字,可以有两位小数